(Proyecto de investigación del Vicerrectorado de Planificación, Estudios, Calidad y Acreditación de la Universitat Politècnica de València. Dirección de Area de Transformación Docente e Instituto de Ciencias de la Educación)
Mientras algunas personas debaten si prohibir o no “ChatGPT” en nuestras aulas, nuestros estudiantes ya lo usan. Porque muchas de las cosas que enseñamos, la IA ya las responde mejor y más rápido. Si no identificamos qué nos hace verdaderamente valiosos como profesorado universitario, corremos el riesgo de volvernos irrelevantes.
Planteo hacer una serie de entradas donde te contaré:
→ Entrada 1: por qué decidimos investigar esto y las preguntas que nos quitan el sueño
→ Entrada 2: qué dicen los estudiantes sobre lo que nos hace insustituibles (siete cosas que valoran y tres alertas rojas)
→ Entrada 3: qué propone el profesorado y hacia dónde vamos con este proyecto
Este proyecto no va de tecnofobia ni de tecnoeuforia. Va de preguntarnos qué deberíamos seguir haciendo, qué transformar radicalmente, y qué quizá dejar de hacer.
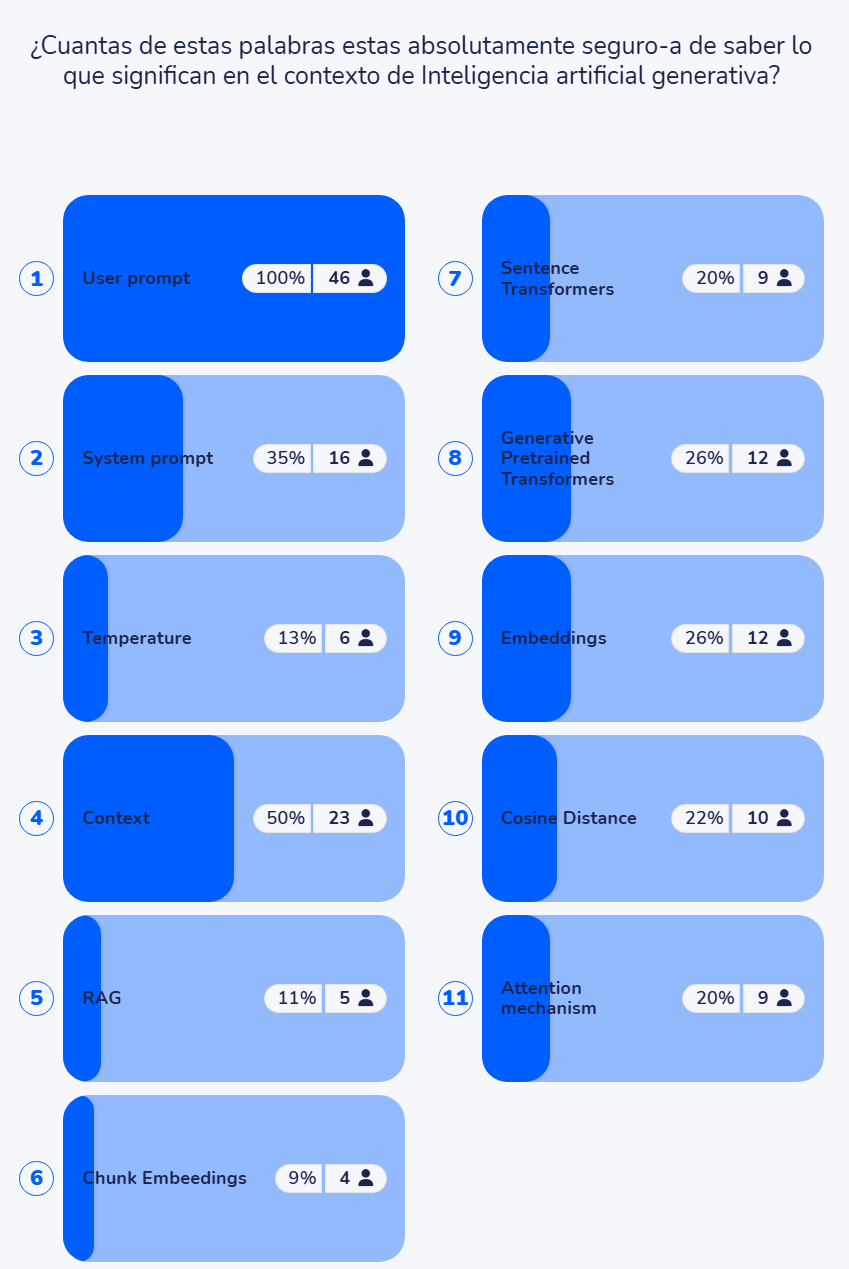
¿que emociones genera en ti cuando oyes “Inteligecia Artificial Generativa”? (50 profesoras-es, noviembre 2025)
En unas jornadas en noviembre 2025 se me ocurrió preguntar si conocían el significado de algunos términos que, para mí, son básicos sobre IA generativa (si no sabes lo que significan dudo mucho que puedas entender cómo funciona y mucho menos pilotarla adecuadamente)
Asistieron unas 50 personas, todas ellas profesoras de universidad, en diferentes titulaciones y departamentos y con diferente trayectoria académica – desde jóvenes recién entradas a catedráticas -, y con cierta sensibilización y práctica como usuarias de Inteligencia Artificial Generativa (no creo que se pudieran considerar “novatas” o que acabaran de descubrir qué es esto de la IAgen).
Y estos son los resultados:
User prompt
(Lo que tú me dices)
Es como cuando tú haces una pregunta o pides algo. Por ejemplo, “cuéntame un cuento” o “ayúdame con mi tarea”. Es lo que TÚ escribes para hablar la IAgen
System prompt
(Las reglas secretas que tengo)
Es como las reglas que los programadores dieron a la IAgen antes de que pudiéramos hablar. Por ejemplo, “sé amable”, “ayuda siempre”, “no digas groserías”. Tú no puedes ver estas reglas, pero la IAgen siempre las sigue
En algunos casos (proyectos, “chat builder” o uso del LLM por API con un script ) puedes “controlar” el System prompt (añadirlo al programado o, en algunos modelos, sustituir el programado)
Temperature
(Qué tan creativo soy)
Imagínate que la IAgen tenga un botón de creatividad. Si está en “frío”, siempre da respuestas muy parecidas y serias. Si está en “caliente”, es más divertida, creativa, impredecible, pero a veces digo cosas raras. Es como elegir entre ser muy formal o muy juguetón
Context
(Lo que recordamos de nuestra conversación)
Es como nuestra memoria de la conversación. Si le dijiste a la IAgen que te gusta el helado de chocolate, lo recuerda para seguir hablando contigo sobre eso. Es todo lo que hemos dicho antes en nuestra charla (hasta el límite que los programadores hayan establecido)
La nueva información sustituye a la más antigua cuando sobrepasa la capacidad y se desborda (olvidando primero lo más antiguo)
Algunas plataformas (como POE) te permiten indicar a ti la amplitud del contexto
RAG
(Buscar información extra)
Es como cuando no sé algo y voy a buscar en una biblioteca especial para darte mejor información. En lugar de solo usar lo que ya sé, voy a buscar datos frescos para ayudarte mejor (uso los Chunk Embeedings para esto)
Chunk Embeedings
(Pedacitos de información organizados)
Imagínate que tienes muchos libros y cortas cada página por cada párrafo. Luego, cada párrafo lo conviertes en un vector (una lista de números). Así la IAgen puede encontrar el párrafo que necesito cuando preguntas algo. Por menos distancia con la pregunta
Embeddings
Imagínate que quieres describir a tu mejor amigo. Podrías decir:
Lo alto es (del 1 al 10)
Lo divertido es (del 1 al 10)
Lo bueno es en matemáticas (del 1 al 10)
Lo deportista es (del 1 al 10)
Entonces, tu amigo sería algo como: [7, 9, 5, 8] – esos son 4 números que lo describen-.
Ahora imagínate que en lugar de 4 cosas, quisieras describir TODAS las características posibles de tu amigo: su humor, inteligencia, creatividad, bondad, si le gustan los animales, si es tímido, si le gusta la música… podrían ser 300 o 1000 características diferentes
Eso es exactamente lo que hace un embedding con las palabras. Toma una palabra como “gato” y la convierte en una lista súper larga de números (como [0.2, -0.5, 0.8, 0.1, -0.3…]) donde cada número representa una característica de esa palabra.
La palabra “perro” tendría números muy parecidos a “gato” porque ambos son animales peludos y mascotas. Pero “avión” tendría números muy diferentes.
Vector n-dimensional
Es el nombre técnico para esa lista súper larga de números. Si tiene 300 números, decimos que es un “vector de 300 dimensiones”. Es como si cada palabra viviera en un espacio gigante con 300 direcciones diferentes, y el vector representa las coordenadas que nos dicen dónde está exactamente en ese espacio.
Por eso las palabras parecidas “viven cerca” en ese espacio invisible y las diferentes “viven lejos”.
Distance (cosine)
Una forma de medir la distancia donde lo que importa es la dirección (no la distancia “euclídea”). Si los vectores apuntan en la misma dirección tienen menos distancia (aunque uno sea más corto o más lejano)
NLP
(Entender el lenguaje humano)
La capacidad de la IAgen para entender lo que se le dice y responderte en tu idioma. Es como ser un traductor súper inteligente que entiende no solo las palabras, sino también lo que realmente quieres decir.
Sentence Transformers vs GPT (Dos tipos diferentes de robots inteligentes)
Sentence Transformers
Una especie de robots que son súper buenos para entender y comparar frases. Son como bibliotecarios que pueden encontrar el libro que “CREEN” que buscas a partir de una información incompleta que les das. Convierten el texto en números (y siempre los mismos números para el mismo texto) en base a los pesos de su entrenamiento. Convierten frases nuevas en embeddings en tiempo real. Cuando les das una frase que nunca han visto antes, la procesan y crean un vector nuevo específicamente para esa frase completa.
Su trabajo es crear representaciones numéricas de frases completas
Son especialistas en capturar el significado de oraciones enteras
Generative Pretrained Transformers
Una especie de robots súper buenos para crear y escribir cosas nuevas. Durante el entrenamiento, ya se calcularon y “congelaron” todos los embeddings de los tokens. Cuando tú escribes algo, tus palabras se convierten en tokens, cada token ya tiene su embedding calculado, Los pesos de todas las conexiones también estaban ya calculados. Solo se comparan los embeddings para seleccionar los que tienen más probabilidad de continuar la secuencia
Durante el entrenamiento fue como afinar cada tecla del piano y ajustar cada cuerda. Ahora, cuando “tocas” una secuencia de teclas (escribes), el piano ya sabe qué sonidos hacer porque ya está todo afinado. Lo que ocurre es que a partir de unas instrucciones que le das (system + user prompts) el piano se dedica a componer e interpretar.
Attention mechanism
Es como cuando lees un cuento y prestas más atención a las partes importantes. Los GPT hacen lo mismo con las palabras: ponen más atención a las palabras que creen que son más importantes de tu pregunta, para darte una “mejor” respuesta.
He comparado la respuesta de Claude-sonnet-4 y las de 4 grupos de estudiantes de máster (5 personas en cada grupo) con un caso que he preparado como diagnóstico inicial para comprobar las competencias de mis estudiantes el primer día de clase.
Mis estudiantes han estado trabajando 2 horas sobre un caso de 5 páginas donde su tarea estaba descrita en un párrafo y el resto era información de contextualización.
El Prompt usado con Claude-sonnet-4 en poe.com era simplemente el párrafo de descripción de la tarea a realizar sin ningún contexto adicional (ni de nivel de estudios, ni de contexto… nada).
“resuelve este caso “”Formas parte de un proyecto que pretende alinear el uso de Inteligencia Artificial (IA) con los valores y objetivos estratégicos de la UPV, de modo que la IA ayude a construir en lugar de minar el futuro que queremos ser. Como grupo, debéis manifestar vuestro punto de vista, como estudiantes universitarios, sobre cómo percibís la IAgen, explorar los problemas o inquietudes que os genera en los diferentes usos o funciones en las que os afecta como estudiantes en la universidad y clasificarlos/filtrarlos. Para acabar proponiendo un listado de recomendaciones (o guías) de uso que sugerís para resolver las causas que originan los problemas que consideráis como principales y un plan para la implementación de esas recomendaciones.”””
Todos los grupos de estudiantes, en lugar de hacer unas guías para estudiantes, han hecho recomendaciones para la universidad o sus equipos directivos. Claude-sonnet-4 ha cometido exactamente el mismo error en la primera iteración. No obstante, su informe ha sido mucho mejor que el de cualquiera de los grupos.
Le he pedido a la IA una segunda iteración: “las recomendaciones que has dado son para la institución, no has respetado la tarea que era crear recomendaciones para los estudiantes. Por otra parte, ajusta el reporte al modelo triple diamante”. En este caso ha clavado las recomendaciones, aunque su interpretación de lo que era el “framework” de triple diamante dejaba mucho que desear, pero le hubiera puesto un 5 o un 6 de nota a ese ejercicio (los ejercicios de mis estudiantes no creo que pasen de un 2 o un 3, pero a ellos no les he dado la oportunidad de repetirlo).
Conclusión:
Cuando les pido a mis estudiantes, a PRINCIPIO de curso que resuelvan un caso y les valoro en base a los resultados de aprendizaje que esperaría que tuvieran a FINAL de curso, la IA generativa les da “mil vueltas” (o por lo menos una decena).
Lo interesante aquí es qué pasará al final del curso cuando mis estudiantes hayan superado los resultados de aprendizaje esperados. La IA generativa no mejorará su nota de 5-6 (salvo que estemos ante un nuevo modelo), entonces creo que serán mis estudiantes los que le darán mil vueltas a la IA generativa.
Extended Title: Action research on designing materials, protocol, and feasibility of a complex intervention to foster critical thinking and apply the triple diamond framework in group decision-making.
This project aims to enhance students’ critical thinking and decision-making skills by developing, testing, and refining a structured group decision-making framework called the triple diamond. It focuses on identifying misconceptions that hinder students’ use of this framework and improving pedagogical interventions through active, collaborative learning and evidence-based methodologies.
Project scope and participants: The innovation will be implemented across multiple courses in engineering, logistics, and business master’s programs, involving diverse student groups facing recurring difficulties in applying structured decision-making methods.
Problem identification: Students consistently rely on intuitive rather than structured approaches in group decisions, struggling to apply the triple diamond framework despite repeated instruction and practice. This issue is persistent and mirrors challenges observed in professional settings.
Theoretical foundations: The project integrates concepts of misconceptions, knowledge elicitation, threshold concepts, and decoding the discipline to reveal and address barriers to expert-like thinking in decision processes. It emphasizes the reorganization of knowledge fragments rather than the mere replacement of incorrect ideas.
Learning objectives: Students will learn to manage group decision processes using the triple diamond, define tasks and prioritization criteria explicitly, analyze innovation competencies, and develop reasoned, evidence-based reports, all enhancing critical thinking skills.
Methodology: The project employs active and collaborative learning through structured three-hour classroom dynamics complemented by autonomous preparatory work. It incorporates innovative visual case representations, reflective learning journals, and think-aloud protocols to elicit student thinking and identify misconceptions.
Expected outcomes: These include identifying common misconceptions, adapting and developing rubrics for assessment, quantifying students’ valuation of innovation competencies, improving decision quality and reducing cognitive biases, and evaluating the impact of different case presentation formats on engagement and critical thinking.
Work plan and tools: The two-year plan details tasks such as material development, rubric adaptation, protocol design, experimental validation, and dissemination through academic articles and conferences. Project management uses O365 tools with regular team meetings and quality control processes.
Evaluation strategy: Evaluation includes measuring the number and categorization of misconceptions, rubric validation, analysis of student preferences and clusters, transferability assessments, pre-post intervention comparisons, and engagement metrics using established models. Data collection involves think-aloud sessions, forum analyses, and observations.
Impact and dissemination: The project aims to improve teaching and learning by making decision-making processes transparent and evidence-based, enabling transfer across disciplines and formats, including MOOCs. Results will be shared via conferences, indexed publications, online platforms, and social media, ensuring broad accessibility and adoption.
Ruiz Martín, H. (2023). “edumitos”: Ideas sobre el aprendizaje sin respaldo científico (1a edición: diciembre 2023). International Science Teaching Foundation.
Hoy pego el índice para que puedas ver si hay temas que te interesan.
A mí, de entrada, me interesan el 1, 2, 6, 7, 8, 9, 11, 14, 16, 17, 18, 19 (junto con 15), 23, 24, 25, 27, 28, 35, 36, 37, 38, 39, 40, 41, 42, 44.
Pensar sin muletas: la importancia del conocimiento ‘inútil’ en un mundo automatizado
He estado escuchando este podcast que os resumo más abajo y la idea que me ha venido a la cabeza (no me preguntéis por qué, son cosas de asociaciones de ideas que van a su bola) es;
Aunque en la vida profesional casi todo el mundo usa calculadoras (u hojas de cálculo), considero muy conveniente aprender “calculo mental” en el colegio y ser solvente con operaciones básicas. No es solo que “amueble” el cerebro. Creo que es esencial para tener algo a lo que siempre me he referido como “idea de la dimensión” y para otras muchas cosas más que son útiles en la vida.
Del mismo modo, no me cabe la menor duda de que en la vida profesional todo el mundo usará IA generativa. Pero considero muy conveniente aprender conocimientos y a hacer cosas que la IA generativa haga incluso mejor que los humanos… no para competir por resultados o eficiencia, simplemente para poder pensar.
Teachlab Presents: The Homework Machine, Episode 1: Buckle Up, Here it Comes”
Ideas Principales
1. Llegada Disruptiva de la IA Generativa
ChatGPT llegó a los espacios educativos en noviembre de 2022 sin invitación institucional. A diferencia de otras tecnologías educativas que las escuelas adoptan planificadamente, la IA generativa “se coló” directamente en manos de los estudiantes a través de sus dispositivos personales.
2. Los centros educativos y los-as docentes han respondido de manera muy heterogénea
3. Impacto en la Dinámica del Aula
Uso de IA para tareas de manera generalizada, creando:
Presión sobre estudiantes honestos-as que se sienten en desventaja
Aceleración artificial del ritmo de clase
Retroalimentación incorrecta para los docentes sobre el aprendizaje real
4. Brecha Entre Promesas y Realidad
Existe una gran diferencia entre las declaraciones optimistas de los desarrolladores de IA y la experiencia caótica que viven realmente educadores y estudiantes.
Utilidad para Profesores Universitarios
Desarrollar políticas claras sobre uso de IA antes de que surjan problemas
Crear espacios de discusión con colegas sobre mejores prácticas
Reconsiderar métodos de evaluación tradicionales que pueden ser fácilmente completados por IA
Incorporar evaluaciones presenciales, orales o procesos reflexivos que demuestren comprensión real
Establecer expectativas claras sobre uso de IA desde el primer día
Enseñar uso adecuado efectivo de IA como herramienta de apoyo, no reemplazo
Adaptar metodologías para aprovechar la IA como recurso educativo
Mantener diálogo con estudiantes sobre desafíos académicos que llevan a usar IA
Explicar por qué ciertos procesos de aprendizaje no deben ser IAgenerativizados
Crear ambiente donde estudiantes se sientan cómodos admitiendo dificultades sin recurrir a IA
Experimentar personalmente con herramientas de IA para entender sus capacidades y limitaciones
Colaborar con colegas para compartir estrategias efectivas
Mantenerse actualizado sobre evolución tecnológica y sus implicaciones educativas
He estado leyendo el artículo de Hestenes et al. (1992) con el objetivo de sacar ideas para el proyecto #PIME_25-26_544 [Investigación acción para el diseño de los materiales, protocolo y análisis de viabilidad de una intervención compleja para analizar el impacto en la mejora del pensamiento crítico y el uso del marco de referencia del triple diamante en la toma de decisiones en grupo]
Hestenes, D., Wells, M., & Swackhamer, G. (1992). Force concept inventory. Physics Teacher, 30(3), 141–158. https://doi.org/10.1119/1.2343497
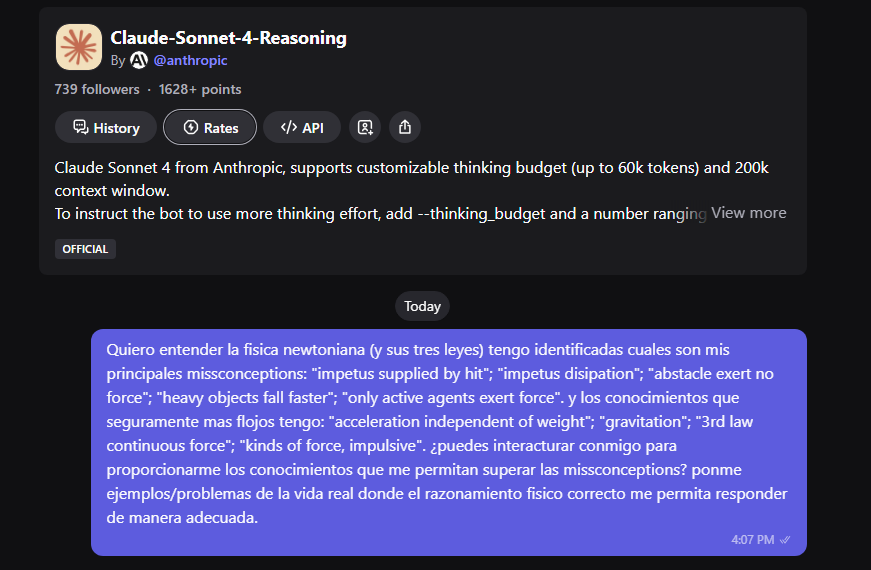
Al acabar de leerlo, me ha picado la curiosidad de comprobar si mis conocimientos de física newtoniana son robustos o estaban plagados de “concepciones alternativas”. He aprovechado que como anexo está el “force concept inventory” (29 preguntas test para diagnosticar las “missconceptions” sobre física newtoniana).
He obtenido 21 respuestas correctas (un 72%), que teniendo en cuenta que son conceptos básicos de Física, podría parecer un poco escaso. No está tan mal al ompararlo con los resultados que muestran los autores para 1500 estudiantes EEUU (de último curso de bachillerato o de primer curso de universidad -incluyendo a Harvard University-). Al empezar el curso el porcentaje de aciertos está entre el 20% y el 25% en estudiantes “normales” de bachillerato; entre el 25% y el 41% los grupos de “altas capacidades”; y de 34% a 52% en universidad. Al acabar el curso suele estar entre 42% y 78% en bachillerato y 63% a 77% en universidad. De modo que mis conocimientos, tras más de 37 años sin haber recibido ninguna instrucción formal sobre física, están al nivel de cuando acabas física de primero de universidad EEUU.
Pero como el force concept inventory también te indica cuales son las “missconceptions” en función de las respuestas que das, se me ha ocurrido jugar con Claude4-sonnet-reasoning. Con este esté sencillo promtpt que aparece en la imagen me ha dado para estar unos 40 minutos respondiendo a las preguntas que me hacía la plataforma.
Dentro de unos meses (cuando ya haya olvidado que respondí hoy) repetiré la prueba a ver si he consolidado el conocimiento.
Mi modelo de aprendizaje fluctúa entre EPLEDRE (denostado por Ahrens (2020) y muchos promotores de 2ndbrain) y zettlekasten/2ndbrain. En ambos casos, todas las etapas del proceso se pueden hacer íntegramente con IAgen, incluso se pueden hacer muy bien (quizás sin diferencias en resultado respecto a un humano o superando a un humano -por supuesto son imbatibles en tiempo, lo que a un humano le puede costar meses o años, lo tienes en minutos con IAgen-. Pero no aprendo lo mismo consumiendo que creando. Cuando trabajo manualmente, cada fragmento de información debe ser leído varias veces. Una cuando los subrayo, otra cuando lo posiciono en el diagrama de afinidad, otra cuando lo codifico y otra cuando lo tengo agrupado por códigos para escritura productiva. Estos 3-4 impactos (como mínimo) hacen que recuerde las cosa (o al menos aumente la probabilidad de que las recuerde), también me dan 4 oportunidades para conectar esa información con ideas, preguntas o intereses. Si tengo métodos abreviados que me automatizan alguno de estos 4 pasos, ahorro tiempo, pero seguramente perderé aprendizaje (o aprenderé de otra forma que no se si será igual de profunda o más superficial).
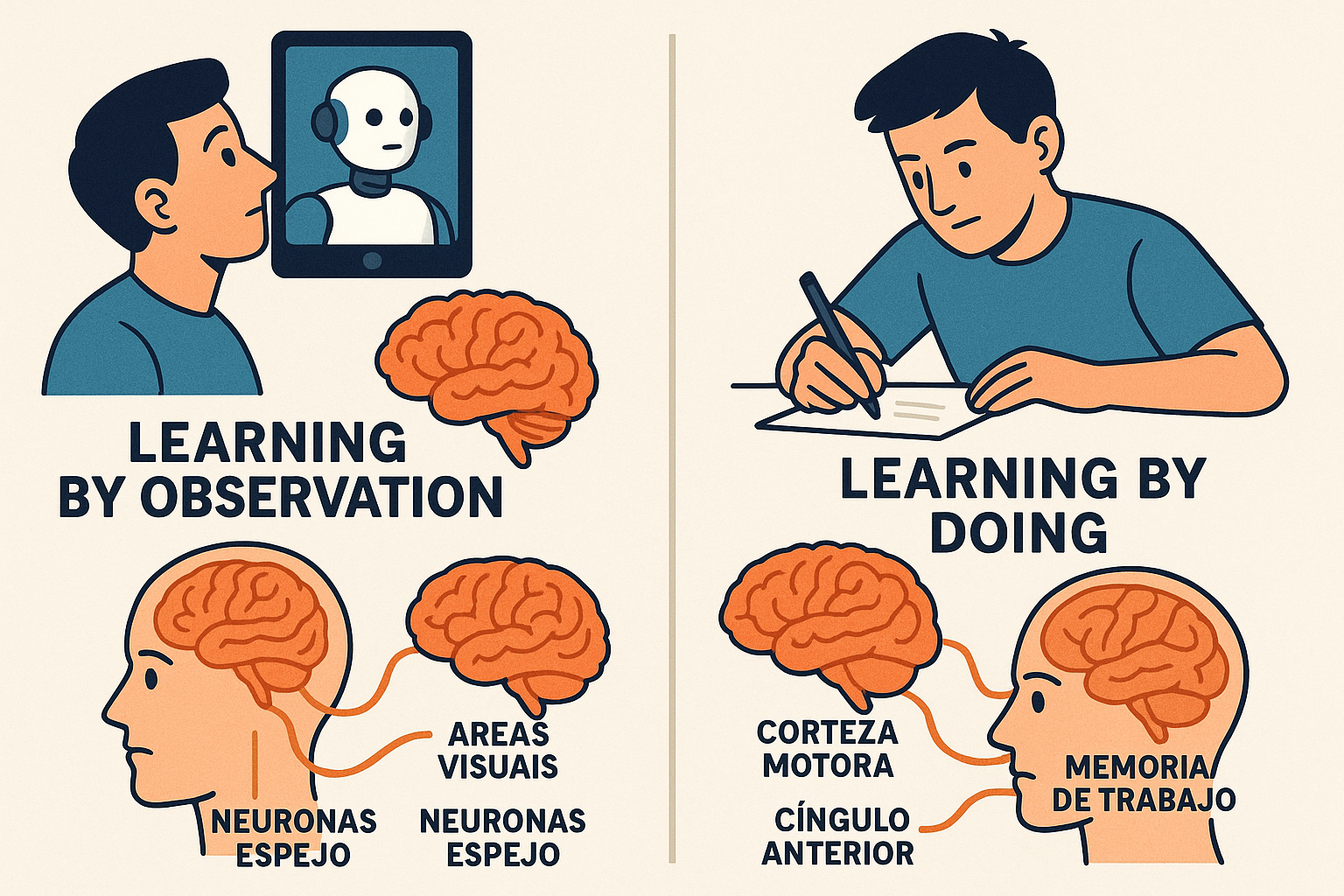
Se me ha ocurrido (no se si con acierto o no), que cuando uso IAgen, estoy haciendo un aprendizaje que podría parecerse a la observación, mientras que si lo hago manualmente es “learning by doing”. Esto me da la oportunidad de intuir que puede pasar en mi aprendizaje aprovechando el conocimiento científico que ya existe sobre estos dos tipos de aprendizaje.
El aprendizaje basado en la práctica (learning by doing) y el aprendizaje por observación (observational learning) se han demostrado efectivos para mejorar el aprendizaje. Pero es posible que no se manifiesten los mismos resultados de aprendizaje, o no con la misma intensidad, con uno y otro. Mientras que “aprender haciendo” permite un aprendizaje experiencial profundo y un desarrollo de habilidades prácticas, “aprender observando” puede centrarse más en la cognición y la asimilación de información a través de la reflexión y el pensamiento crítico. Estos métodos activan diferentes sistemas cognitivos. Cuando simplemente observamos a alguien hacer algo, nuestro cerebro activa principalmente las neuronas espejo (ubicadas en áreas frontales y parietales) y las zonas visuales, que nos permiten entender lo que vemos pero sin comprometer completamente nuestros sistemas de control. Sin embargo, cuando ejecutamos esas mismas acciones, la cosa es diferente. Para movimientos físicos se activan intensamente la corteza motora (que controla nuestros músculos), el cerebelo (que coordina los movimientos) y los ganglios basales (que automatizan secuencias), además de áreas sensoriales que procesan el tacto y la posición de nuestro cuerpo. Cuando intentamos una accion mental como resolver problemas, la ejecución activa dispara mucho más intensamente la corteza prefrontal (nuestra “zona ejecutiva” que planifica y toma decisiones), áreas de memoria de trabajo en regiones parietales, y el cíngulo anterior (que monitoriza errores y conflictos) que se podría asociar al procesamiento metacognitivo. Además, durante la observación, la activación cerebral tiende a ser más bilateral y distribuida. Es decir, genera un procesamiento mas general. , mientras que la ejecución fuerza al cerebro a comprometer recursos especializados de cada hemisferio, creando representaciones más específicas y lateralizadas que son más eficientes pero también más especializadas para tipos particulares de tareas.
Un ejemplo, en deporte puedes aprender o interiorizar tácticas o esquemas de juego a partir de visionado de vídeos. Sus ventajas son indudables (hace viable ejercicios que no podrían hacerse en directo por falta de recursos o por condiciones meteorológicas u otras variables de contexto; no agota físicamente, de modo que puedes repetir sesiones sin sobrecargar musculatura; da un punto de vista que es difícil de lograr en el campo; permite parar, pausar, comentar y repetir mucho más flexible que en el campo…). Sin embargo, el impacto en tu forma física es nulo cuando ves un partido y la mejoras cuando juegas uno. De modo que no se aprende lo mismo consumiendo que haciendo.
Con menos de dos días de diferencias he leído dos documentos en la red que me han hecho pensar una cosa y la contraria.
El primero, cronológicamente hablando, ¡Me falta fe en mis alumnos! ¡Me falta fe en el sistema! – Universidad, sí habla del cambio del contexto profesional/social a lo largo del tiempo. Por ello, lo que debe ser aprendido y cómo debe ser aprendido, debe adaptarse al modo en que va a ser aplicado en este nuevo contexto.
En él, se plantean algunas preguntas que me parecen relevantes e interesantes: ¿Estamos siendo verdaderos catalizadores del proceso de aprendizaje actual? ¿Ayudamos a nuestros estudiantes en su proceso de crecimiento? ¿Tenemos que seguir exigiendo lo mismo a nuestros estudiantes? ¿Podemos seguir enseñando igual cuando la realidad no es igual? ¿Cómo podemos mejorar nuestra docencia? ¿Pueden aprender los estudiantes lo mismo por sí solos, sin ayuda o apoyo de una-a docente? ¿Hay diferencia entre que asistan presencialmente o interactúen con profesorado compañeros-as en una pantalla? ¿Impacta que tengan el curriculum dirigido o que elijan los-as estudiantes lo que quieren aprender?
El segundo, The Elite College Students Who Can’t Read Books – The Atlantic , comenta la experiencia en USA en titulaciones universitarias relacionadas con la literatura donde los-as estudiantes no son capaces de leer libros completos porque en secundaria y en bachillerato no han leído nunca un libro completo. Me ha generado dudas sobre si el camino de las “Pildoras” de conocimiento tipo “media UPV” es un buen camino o no. Evidentemente es práctico y permite crear cursos modulares. Supongo que un curso completo es el equivalente a la experiencia de leer un libro. Pero si nuestros estudiantes consumen la píldora en youtube en lugar cursar el curso completo…
Entonces ¿hay que adaptarse a los tiempos o intentar transformar aquellas cosas del tiempo actual que no compartimos (a pesar de que “aparentemente” somos pocos las que no las compartimos)?
Una cosa que me resulta muy interesante son los vínculos de realimentación que existen entre la capacidad de resolver problemas, la creatividad, el pensamiento crítico y la memoria… memorizar o recordar cosas no es el fin, es el medio para que habilidades más complejas tengan un material sobre el que trabajar.
No estoy seguro de lo que digo, pero creo que es muy complicado (si no imposible) resolver problemas, ser creativo o ser critico si TODA tu memoria de datos-hechos-modelos reside en el ordenador y no guardas una parte importante en tu cerebro. Un debate interesante es cuánta debe ser esa parte y cómo se entrena a nuestros cerebros para que decidan gastar energía en crear un almacenamiento a largo plazo en lugar de dejar pasar la información sin ni siquiera fijarla en la memoria de trabajo a corto plazo.
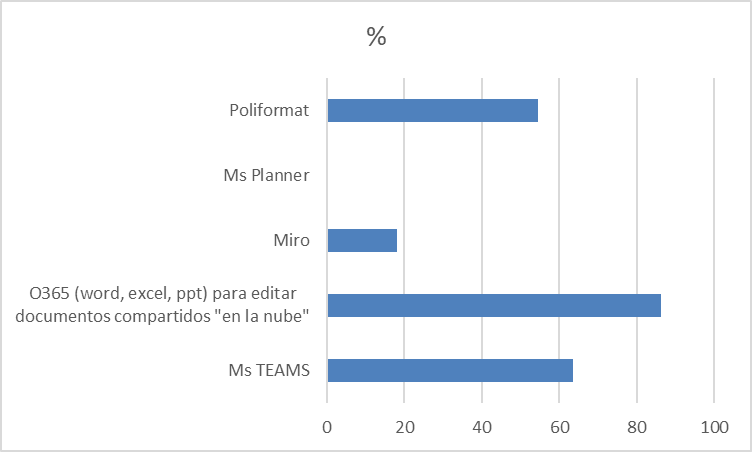
La muestra es pequeña y de conveniencia, pero este es el perfil de mis estudiantes este año. Si no hubiera ocurrido la DANA nadie habría usado TEAMS (y por lo tanto no están acostumbrados-as a este tipo de plataformas). Casi nadie usa Miro y nadie usa planner o similar (no están acostumbrados-as a pensar en gestión de su tiempo por tareas)
2025-7 estudiantes de 3º de grado de ingeniería de la rama industrial
El año anterior era una situación era parecida pero más familiarizados con TEAMS
2024- 22 estudiantes de 3º de grado de ingeniería de la rama industrial