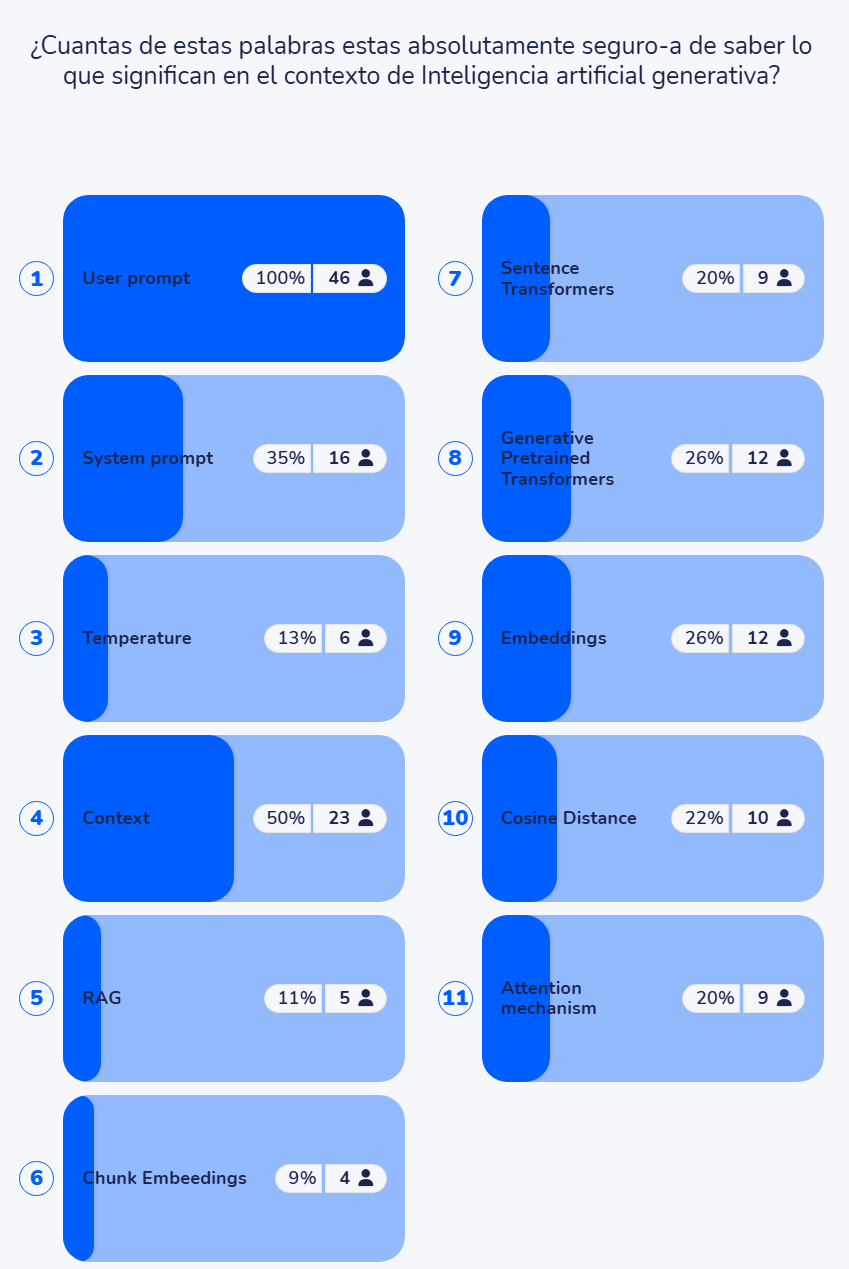
En unas jornadas en noviembre 2025 se me ocurrió preguntar si conocían el significado de algunos términos que, para mí, son básicos sobre IA generativa (si no sabes lo que significan dudo mucho que puedas entender cómo funciona y mucho menos pilotarla adecuadamente)
Asistieron unas 50 personas, todas ellas profesoras de universidad, en diferentes titulaciones y departamentos y con diferente trayectoria académica – desde jóvenes recién entradas a catedráticas -, y con cierta sensibilización y práctica como usuarias de Inteligencia Artificial Generativa (no creo que se pudieran considerar “novatas” o que acabaran de descubrir qué es esto de la IAgen).
Y estos son los resultados:
-
User prompt
-
- (Lo que tú me dices)
- Es como cuando tú haces una pregunta o pides algo. Por ejemplo, “cuéntame un cuento” o “ayúdame con mi tarea”. Es lo que TÚ escribes para hablar la IAgen
-
System prompt
- (Las reglas secretas que tengo)
- Es como las reglas que los programadores dieron a la IAgen antes de que pudiéramos hablar. Por ejemplo, “sé amable”, “ayuda siempre”, “no digas groserías”. Tú no puedes ver estas reglas, pero la IAgen siempre las sigue
- En algunos casos (proyectos, “chat builder” o uso del LLM por API con un script ) puedes “controlar” el System prompt (añadirlo al programado o, en algunos modelos, sustituir el programado)
-
Temperature
- (Qué tan creativo soy)
- Imagínate que la IAgen tenga un botón de creatividad. Si está en “frío”, siempre da respuestas muy parecidas y serias. Si está en “caliente”, es más divertida, creativa, impredecible, pero a veces digo cosas raras. Es como elegir entre ser muy formal o muy juguetón
-
Context
- (Lo que recordamos de nuestra conversación)
- Es como nuestra memoria de la conversación. Si le dijiste a la IAgen que te gusta el helado de chocolate, lo recuerda para seguir hablando contigo sobre eso. Es todo lo que hemos dicho antes en nuestra charla (hasta el límite que los programadores hayan establecido)
- La nueva información sustituye a la más antigua cuando sobrepasa la capacidad y se desborda (olvidando primero lo más antiguo)
- Algunas plataformas (como POE) te permiten indicar a ti la amplitud del contexto
-
RAG
- (Buscar información extra)
- Es como cuando no sé algo y voy a buscar en una biblioteca especial para darte mejor información. En lugar de solo usar lo que ya sé, voy a buscar datos frescos para ayudarte mejor (uso los Chunk Embeedings para esto)
-
Chunk Embeedings
- (Pedacitos de información organizados)
- Imagínate que tienes muchos libros y cortas cada página por cada párrafo. Luego, cada párrafo lo conviertes en un vector (una lista de números). Así la IAgen puede encontrar el párrafo que necesito cuando preguntas algo. Por menos distancia con la pregunta
-
Embeddings
- Imagínate que quieres describir a tu mejor amigo. Podrías decir:
- Lo alto es (del 1 al 10)
- Lo divertido es (del 1 al 10)
- Lo bueno es en matemáticas (del 1 al 10)
- Lo deportista es (del 1 al 10)
- Entonces, tu amigo sería algo como: [7, 9, 5, 8] – esos son 4 números que lo describen-.
- Ahora imagínate que en lugar de 4 cosas, quisieras describir TODAS las características posibles de tu amigo: su humor, inteligencia, creatividad, bondad, si le gustan los animales, si es tímido, si le gusta la música… podrían ser 300 o 1000 características diferentes
- Eso es exactamente lo que hace un embedding con las palabras. Toma una palabra como “gato” y la convierte en una lista súper larga de números (como [0.2, -0.5, 0.8, 0.1, -0.3…]) donde cada número representa una característica de esa palabra.
- La palabra “perro” tendría números muy parecidos a “gato” porque ambos son animales peludos y mascotas. Pero “avión” tendría números muy diferentes.
- Vector n-dimensional
- Es el nombre técnico para esa lista súper larga de números. Si tiene 300 números, decimos que es un “vector de 300 dimensiones”. Es como si cada palabra viviera en un espacio gigante con 300 direcciones diferentes, y el vector representa las coordenadas que nos dicen dónde está exactamente en ese espacio.
- Por eso las palabras parecidas “viven cerca” en ese espacio invisible y las diferentes “viven lejos”.
- Imagínate que quieres describir a tu mejor amigo. Podrías decir:
-
Distance (cosine)
- Una forma de medir la distancia donde lo que importa es la dirección (no la distancia “euclídea”). Si los vectores apuntan en la misma dirección tienen menos distancia (aunque uno sea más corto o más lejano)
-
NLP
- (Entender el lenguaje humano)
- La capacidad de la IAgen para entender lo que se le dice y responderte en tu idioma. Es como ser un traductor súper inteligente que entiende no solo las palabras, sino también lo que realmente quieres decir.
- Sentence Transformers vs GPT (Dos tipos diferentes de robots inteligentes)
-
Sentence Transformers
- Una especie de robots que son súper buenos para entender y comparar frases. Son como bibliotecarios que pueden encontrar el libro que “CREEN” que buscas a partir de una información incompleta que les das. Convierten el texto en números (y siempre los mismos números para el mismo texto) en base a los pesos de su entrenamiento. Convierten frases nuevas en embeddings en tiempo real. Cuando les das una frase que nunca han visto antes, la procesan y crean un vector nuevo específicamente para esa frase completa.
- Su trabajo es crear representaciones numéricas de frases completas
- Son especialistas en capturar el significado de oraciones enteras
-
Generative Pretrained Transformers
- Una especie de robots súper buenos para crear y escribir cosas nuevas. Durante el entrenamiento, ya se calcularon y “congelaron” todos los embeddings de los tokens. Cuando tú escribes algo, tus palabras se convierten en tokens, cada token ya tiene su embedding calculado, Los pesos de todas las conexiones también estaban ya calculados. Solo se comparan los embeddings para seleccionar los que tienen más probabilidad de continuar la secuencia
- Durante el entrenamiento fue como afinar cada tecla del piano y ajustar cada cuerda. Ahora, cuando “tocas” una secuencia de teclas (escribes), el piano ya sabe qué sonidos hacer porque ya está todo afinado. Lo que ocurre es que a partir de unas instrucciones que le das (system + user prompts) el piano se dedica a componer e interpretar.
-
Attention mechanism
- Es como cuando lees un cuento y prestas más atención a las partes importantes. Los GPT hacen lo mismo con las palabras: ponen más atención a las palabras que creen que son más importantes de tu pregunta, para darte una “mejor” respuesta.
Visitas: 31









{kind=link}